Создание нейронной сети на Python
Создание нейронной сети с использованием Google Colab, Kaggle и fastai: как это работает?
Нейронные сети: цифровой мозг, который учится
Нейронные сети — это алгоритмы, вдохновленные работой человеческого мозга. Они состоят из слоев "нейронов" (математических функций), которые обрабатывают данные, учатся находить закономерности и делают предсказания. Например, чтобы отличить кошку от собаки на фото, сеть анализирует тысячи пикселей, выявляя признаки вроде формы ушей или длины хвоста.
Обучение нейросетей — это как настройка гитарных струн:
- Данные: Нужен датасет (например, фото машин с метками "повреждена" / "не повреждена").
- Ошибка: Сеть делает предположение, сравнивает его с правильным ответом и вычисляет, насколько ошиблась (loss).
- Оптимизация: Алгоритм (вроде SGD или Adam) корректирует "веса" нейронов, чтобы снизить ошибку.
- Повторение: Цикл длится сотни или тысячи раз (эпох), пока модель не научится.
Чем сложнее архитектура сети (например, ResNet, YOLO), тем лучше она справляется с задачами вроде классификации изображений — как в вашем проекте!
Google Colab: облачная лаборатория для экспериментов
Google Colab — это бесплатный Jupyter-ноутбук в облаке. Зачем он вам?
- GPU/TPU ускорение: Обучение нейросетей требует мощных видеокарт. Colab предоставляет их бесплатно (сессия до 12 часов).
- Нулевая настройка: Не нужно устанавливать CUDA, PyTorch или TensorFlow — всё уже готово.
- Совместная работа: Можно делиться кодом как документом Google.
- Интеграция с Google Диском: Легко загружать датасеты и сохранять модели.
Ваш проект идеально подходит для Colab: здесь есть GPU для обучения модели, а библиотеки вроде fastai уже предустановлены.
Разбор кода: как наш проект определяет повреждения машин
Вот полный код проекта, который мы будем использовать:
# Установка зависимостей
!pip install fastai --quiet
from fastai.vision.all import *
from pathlib import Path
import torch
import zipfile
from google.colab import files
def main():
# Установка устройства (GPU, если доступен)
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
print(f"Используемое устройство: {device}")
# 1. Загрузка zip-файла с датасетом
print("Загрузите zip-файл с датасетом...")
uploaded = files.upload() # Выберите zip-файл с датасетом
dataset_zip = list(uploaded.keys())[0]
dataset_path = Path("/content/dataset")
dataset_path.mkdir(parents=True, exist_ok=True)
# Распаковка zip-файла
print(f"Распаковка файла {dataset_zip}...")
with zipfile.ZipFile(dataset_zip, "r") as zip_ref:
zip_ref.extractall(dataset_path)
# Проверяем содержимое папки
print(f"Файлы в {dataset_path}:")
!ls {dataset_path}
# 2. Проверка и удаление поврежденных изображений
print("Проверка изображений...")
failed = verify_images(get_image_files(dataset_path))
if len(failed) > 0:
print(f"Удаление {len(failed)} поврежденных изображений...")
failed.map(Path.unlink)
# 3. Создание DataBlock с аугментациями
print("Создание DataBlock с аугментациями...")
dls = DataBlock(
blocks=(ImageBlock, CategoryBlock), # Типы данных: изображения и категории
get_items=get_image_files, # Получение путей к изображениям
splitter=GrandparentSplitter(train_name='training', valid_name='validation'), # Разделение данных
get_y=parent_label, # Получение меток из названия папки
item_tfms=[Resize(192, method='squish')], # Преобразование размеров изображений
batch_tfms=[
*aug_transforms(size=192, flip_vert=True), # Аугментации
Normalize.from_stats(*imagenet_stats) # Нормализация
]
).dataloaders(dataset_path, bs=32, device=device) # Передаём устройство в DataLoaders
# 4. Показ примеров изображений
print("Показ примеров данных...")
dls.show_batch(max_n=9)
# 5. Создание и обучение модели
print("Создание и обучение модели...")
learn = vision_learner(dls, resnet34, metrics=error_rate, wd=1e-2).to_fp16() # Используем float16 для ускорения
learn.fine_tune(20) # Увеличьте количество эпох для лучшего результата
# 6. Загрузка тестового изображения
print("Загрузите тестовое изображение для проверки...")
uploaded_test_image = files.upload() # Загрузка изображения
test_img_name = list(uploaded_test_image.keys())[0]
test_img_path = Path(test_img_name)
# 7. Предсказание на тестовом изображении
if not test_img_path.exists():
print(f"Тестовое изображение '{test_img_path.name}' не найдено.")
else:
img = PILImage.create(test_img_path)
is_damaged, _, probs = learn.predict(img)
# Вывод результата
if is_damaged == '00-damage':
print(f"Модель предсказала: Машина повреждена. Вероятность: {probs[0] * 100:.2f}%.")
else:
print(f"Модель предсказала: Машина не повреждена. Вероятность: {probs[1] * 100:.2f}%.")
if __name__ == '__main__':
main()1. Установка зависимостей
!pip install fastai --quiet
- fastai — высокоуровневая библиотека для глубокого обучения. Упрощает работу с данными, аугментациями и обучением моделей.
--quietубирает лишние сообщения в выводе.
2. Импорты
from fastai.vision.all import *
from pathlib import Path
import torch
import zipfile
from google.colab import files
- fastai.vision.all — модуль для работы с изображениями (DataBlock, аугментации, предобученные модели).
- Path — удобный способ работы с путями файлов.
- torch — фреймворк для тензорных вычислений и нейросетей.
- zipfile и files — для распаковки датасета и загрузки файлов в Colab.
3. Настройка устройства
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
- Проверяет, доступен ли GPU (CUDA). Если да — вычисления выполняются на видеокарте, что ускоряет обучение в 10-100 раз. Так же стоит упомянуть, что обучение на CPU влечет за собой кучу багов.
4. Загрузка датасета
uploaded = files.upload()
dataset_zip = list(uploaded.keys())[0]
files.upload()открывает диалог выбора файла в Colab. Предполагается, что датасет — это ZIP-архив с папкамиtrainingиvalidation, внутри которых подпапки с классами (например,00-damage,01-whole).
5. Распаковка и проверка данных
with zipfile.ZipFile(dataset_zip, "r") as zip_ref:
zip_ref.extractall(dataset_path)
- Распаковывает архив в папку
/content/dataset.
Проверка изображений:
failed = verify_images(get_image_files(dataset_path))
failed.map(Path.unlink)
verify_imagesнаходит битые файлы (например, с нулевым размером), аPath.unlinkих удаляет. Это критично, иначе обучение прервется с ошибкой.
6. DataBlock — сердце подготовки данных
dls = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=GrandparentSplitter(train_name='training', valid_name='validation'),
get_y=parent_label,
item_tfms=[Resize(192, method='squish')],
batch_tfms=[*aug_transforms(size=192, flip_vert=True), Normalize.from_stats(*imagenet_stats)]
).dataloaders(dataset_path, bs=32, device=device)
- blocks: Указывает тип данных — изображения (
ImageBlock) и метки-категории (CategoryBlock). - get_items: Собирает все изображения через
get_image_files. - splitter:
GrandparentSplitterделит данные на тренировочные и валидационные по имени родительской папки (training/validation). - get_y: Метка класса берется из названия родительской папки (
parent_label). - item_tfms: Преобразования для каждого изображения.
Resize(192)изменяет размер до 192x192 пикселей (методsquish"сжимает" изображение без обрезки). - batch_tfms: Аугментации для всего батча: повороты, отражения, изменение яркости (
aug_transforms), а также нормализация по статистике ImageNet.
Важно: Аугментации помогают модели обобщать данные и избегать переобучения. Например, если в датасете все поврежденные машины сфотографированы под одним углом, аугментации создадут "вариации" этого угла.
7. Визуализация данных
dls.show_batch(max_n=9)
- Показывает 9 изображений из батча с метками. Это помогает убедиться, что данные загружены корректно.
8. Создание модели
learn = vision_learner(dls, resnet34, metrics=error_rate, wd=1e-2).to_fp16()
vision_learnerсоздает модель для классификации изображений.- resnet34 — предобученная архитектура (34 слоя). Fastai автоматически заменяет последний слой на подходящий под ваши классы.
- metrics=error_rate — метрика качества (доля неправильных предсказаний).
- wd=1e-2 — вес decay (регуляризация) для предотвращения переобучения.
.to_fp16()— использует половинную точность (float16), чтобы ускорить обучение и уменьшить потребление памяти.
9. Обучение
learn.fine_tune(20)
fine_tuneадаптирует предобученную модель под вашу задачу.- 20 эпох — 20 полных проходов через датасет. В fastai есть встроенные советы по выбору количества эпох, но 20 — разумный старт для большинства задач. И по нашим тестам 20 эпох хватает с головой для проекта.
10. Предсказание на новом изображении
img = PILImage.create(test_img_path)
is_damaged, _, probs = learn.predict(img)
PILImage.createзагружает изображение.learn.predictвозвращает метку класса, индекс и вероятности для каждого класса.
Тренировка и использование модели
Тренировать нашу модель мы будем используя Google Collab. Вы могли бы спросить меня: А почему я не могу тренировать модель у себя на пк?
Основная проблема в том, что разные библиотеки поддерживают разные видеоадаптеры для тренировки моделей, при написании проекта мы столкнулись с тем, что это реально проблема ибо это руководство должно быть полезно всем людям а не только тем, чья видеокарта есть в списке поддерживаемых.
После того, как мы разобрались с кодом, пора перейти на сам Google Collab: вот ссылка: https://colab.research.google.com/?hl=ru (С помощью CTRL + Левая кнопка мыши вы можете открыть сайт в новой вкладке)
Далее стрелочками будет отмечено то, что нужно нажимать после того, как вы перешли Google Collab:
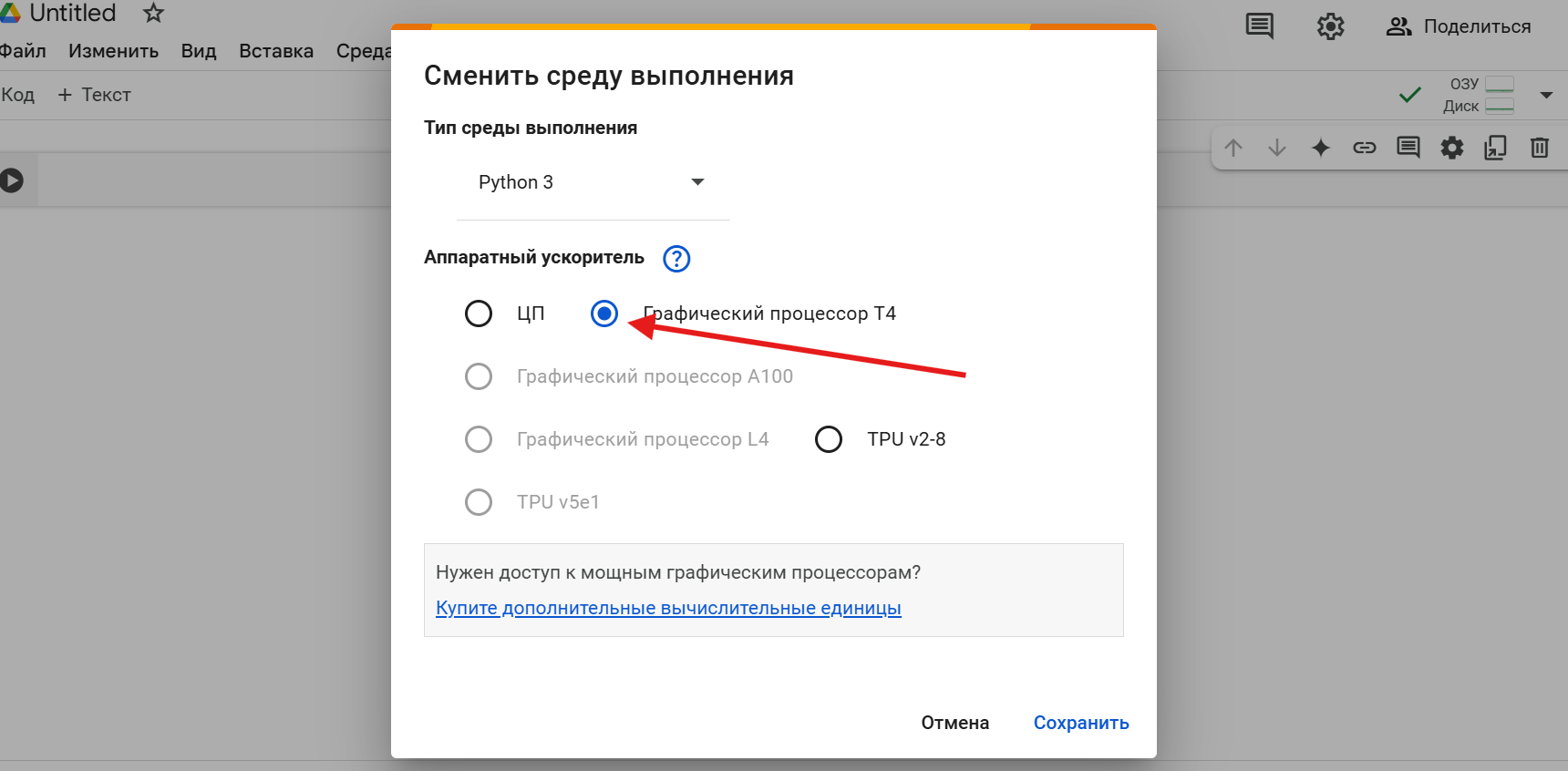
Нажимаем Сохранить, а далее нажимаем подключиться в том же углу и у нас должна появится такая картина:
Далее вставляем наш код в поле для кода и переходим в Kaggle для скачки нужного нам дата сета(архива с данными)
Но для начала разберемся в том: а что это вообще всё такое?
!Предупреждение:
Гугл не разглашает то, какое количество ресурсов мы можете использовать в бесплатном тарифе(Примерно 8 часов беспрерывного использования) и он так же не разглашает то, через какое время после использования все ресурсов вы опять сможете пользоваться видеоадаптером в бесплатном тарифе(Срок ожидания примерно 1 - 3 дня). Тренировать модели можно так же в Kaggle, о котором будет далее.
Kaggle: Playground для Data Scientist’а
Kaggle — это крутая соцсеть для любителей данных. Здесь можно:
- Соревноваться: Участвовать в хакатонах с призовыми фондами до $100k.
- Брать датасеты: Огромная библиотека готовых наборов данных — от фото котиков до медицинских снимков.
- Крутить модели на бесплатном GPU: Как в Colab, но с лимитом 30 часов в неделю.
- Учиться: Куча ноутбуков (kernels) с решениями задач.
Ваш проект мог бы стартовать именно здесь: скачать датасет, подключить GPU, а потом выложить код в виде kernel — и собрать лайки от комьюнити 😎.
Что такое датасет и почему именно «Car Damage Detection»?
Датасет — это коллекция данных + меток. В нашем случае:
- Изображения машин (поврежденных и целых).
Структура папок как «дорожные знаки» для модели:
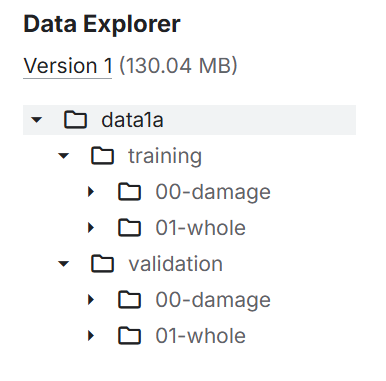
/training /00-damage --> фото с вмятинами, царапинами /01-whole --> машины без дефектов /validation /00-damage /01-whole
Почему этот датасет — отличный выбор?
- Готовое разделение на train/valid:
- Мы не случайно перемешали данные и не разорвали логические связи (например, кадры из одного видео попали в оба сета).
- Валидация отражает реальное распределение классов — метрики будут честными.
- Четкие метки через папки:
- Fastai сам понимает, что
parent_label()= имя папки (00-damage). Не нужно вручную парсить CSV.
- Fastai сам понимает, что
- Баланс классов:
- Если в
training/00-damageиtraining/01-wholeпримерно поровну фото — модель не «перекосится» в сторону одного класса.
- Если в
- Реалистичные данные:
- Предположу, что в датасете — фото разных машин, ракурсов и освещения. Это учит модель обобщать, а не запоминать артефакты.
Как бы это выглядело, если бы структура была плохой?
Представьте, что все фото свалены в одну папку, а метки — в CSV где-то на стороне. Ваш код превратился бы в квест:
# Костыли пришлось бы городить вот такие:
df = pd.read_csv('messy_labels.csv')
def get_y(filename):
return df[df['image_name'] == filename.name]['label'] # ужас!
Вывод: структура с папками — это как шведский стол: всё разложено по полочкам, бери и обучай.
Советы по улучшению датасета
Даже хороший датасет можно сделать круче:
- Добавить маски дефектов: Если кроме метки «повреждена» есть разметка областей повреждений (пиксельные маски), модель сможет находить где именно дефект.
- Больше вариативности: Фото ночью, под дождем, с бликами.
- Баланс по типам повреждений: Чтобы модель не думала, что «царапина = всегда повреждение», а «трещина стекла = нет».
Вот ссылка на нужный нам датасет:
https://www.kaggle.com/datasets/anujms/car-damage-detection
Далее скачиваем датасет в виде zip архива:
Как я уже написал, нам нужно вставить код и начать его выполнение, нажав на кнопку запуска:
Внизу будет виден ход работы программы, нам следует добавить наш архив с датасетом при его запросе:
После добавления архива будет примерно такая картина:

Проценты справа показывают то, на сколько добавлен наш архив с дата сетом, дата сет не маленький поэтому добавляться он будет относительно не быстро, примерно 10-30 минут в зависимости от скорости вашего интернета.
Пока выполняется загрузка архива вы можете скачать одну или сразу две картинки на которых изображена машина с дефектами и без дефектов:
Вот ссылка на машину с явными дефектами - https://cloud.mail.ru/public/6Fzr/72gx89vsg
Вот ссылка на новую машину без дефектов - https://cloud.mail.ru/public/4eZP/6DAM8eYUS

После того как архив загрузится пойдет процесс обучения с таким количеством эпох, которое мы указали:
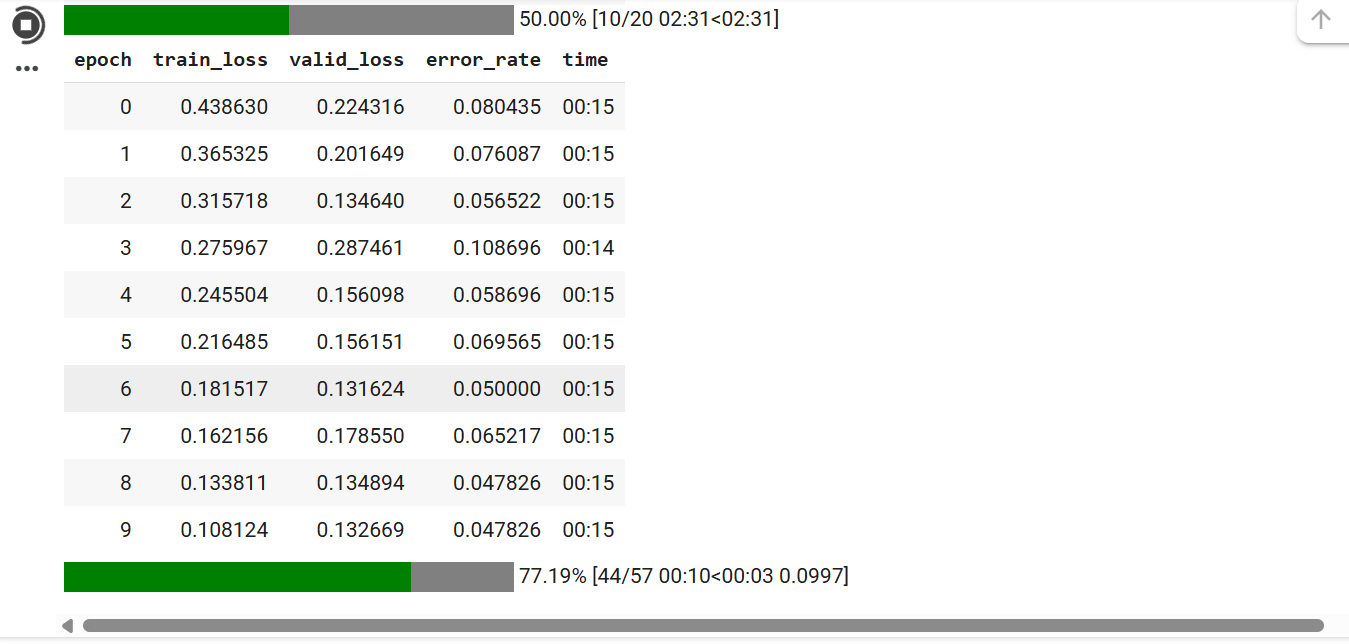
Этот процесс не долгий и 20 эпох на видеоадаптере T4 проходят примерно за 5 минут
- Epoch:
- Epoch обозначает эпоху обучения. Одна эпоха представляет собой полный цикл прохода по всему тренировочному набору данных. В процессе обучения модели обычно проводится несколько эпох, чтобы модель могла усвоить паттерны в данных.
- Train Loss:
- Train Loss (потери на обучающем наборе) указывает на ошибку модели при предсказании значений на тренировочных данных. Это значение показывает, насколько хорошо модель обучается на данных, по которым она была тренирована. Чем ниже это значение, тем лучше модель подходит к тренировочным данным.
- Valid Loss:
- Valid Loss (потери на валидационном наборе) указывает на ошибку модели при предсказании значений на валидационных данных, которые не использовались для обучения модели. Это значение помогает определить, насколько хорошо модель может обобщать и предсказывать на новых, ранее не виденных данных. Низкое значение valid loss указывает на хорошую обобщающую способность модели.
- Error Rate:
- Error Rate (уровень ошибок) показывает процент неправильных предсказаний модели на валидационных данных. Это метрика эффективности модели, где более низкие значения указывают на лучшее качество модели.
- Time:
- Time указывает на время, затраченное на обучение модели в каждой эпохе. Это значение может помочь оценить производительность и скорость обучения модели.
После того, как пройдут все эпохи программа просит нас загрузить одну из фотографий, я в этом запуске загружу машину car2.jpg имеющую явные дефекты:
И вот результат:

Картинки с машинами это примеры из датасета, вывод которых заложен в программе просто для примера, что содержится в датасете, вы можете спокойно убрать вывод этих картинок из программы.
Модель предсказала, что машина повреждена с вероятностью 99.96 процентов, эта вероятность является очень хорошим показателем.
Далее при повторном запуске и отправке исправной car4.jpg мы увидели такой результат:

Заключение: Как наша нейронная сеть меняет правила игры (и не только для машин)
Наш проект — это не просто классификатор «Царапина vs Целое». Это инструмент, который решает реальную проблему: автоматизация визуального анализа. Вместо часов, потраченных на осмотр машины, нейронка выдает вердикт за секунды. Такие системы уже меняют мир:
Tesla использует компьютерное зрение для оценки повреждений после аварий — данные помогают роботам-мастерским быстрее чинить автомобили.
Страховые компании (например, Lemonade) внедряют нейросети для мгновенного расчета выплат по фото.
Каршеринги (вроде BelkaCar) проверяют состояние машин перед арендой, чтобы снизить риски.
Но это только начало. Наша модель — база для сотни других решений. Замените папки с машинами на другие данные — и нейросеть превратится в:
Экологического инспектора: распознает редких птиц по фото или отслеживает вырубку лесов.
Медицинского ассистента: диагностирует кожные заболевания (как сервис SkinVision) или анализирует рентген-снимки.
Фермерского помощника: определяет болезни растений (проекты вроде Plantix) или сортирует урожай.
Модного эксперта: подбирает одежду по стилю (пример — приложение StyleSnap от Amazon).
Как это работает? Архитектура вроде ResNet (как в нашем проекте) — это «скелет», который можно «нарастить мышцами» под любую задачу. Замените датасет — и та же нейросеть научится находить трещины в асфальте, отличать поддельные кроссовки от настоящих или сортировать мемы по категориям.
Главный секрет — в transfer learning (переносе знаний). Наша модель, обученная на автомобилях, уже умеет выделять границы, текстуры и формы. Эти навыки пригодятся для любой задачи, связанной с изображениями. Это как если бы Шерлок Холмс, научившись расследовать кражи машин, вдруг начал раскрывать дела о пропавших котах — логика-то та же!
Что дальше?
Подключить YOLO — чтобы модель не только классифицировала, но и отмечала повреждения на фото.
Сделать Telegram-бота для страховщиков: клиент загружает фото → бот выдает отчет.
Обучить модель на 3D-сканах машин — для точной оценки глубины вмятин.
Наша нейросеть — это как первый пазл в большой картине. Соберите вокруг нее новые данные, доработайте код — и вы сможете менять хоть целые индустрии. Ведь даже Tesla когда-то начинала с одной строчки кода. 🚀
Добавлено: 27 октября 2024 г. 10:40, всего 1594 просмотра.